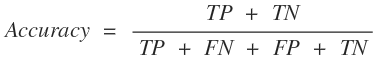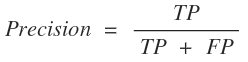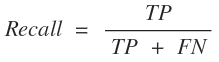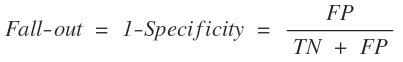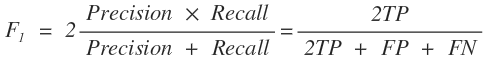1. 문제의 배경
기존의 검색 기반 언어 모델(Retrieval-Augmented Language Models)은 보통 문서를 고정 길이의 짧은 청크(예: 100토큰)로 나눈 후, 이들 중 몇 개만 선택해 LLM(대형 언어 모델)에 입력합니다.
이러한 방식은 문서 전체의 구조나 주제의 흐름, 여러 부분에 걸친 연관 정보를 포착하기 어렵다는 한계가 있습니다. 예를 들어, 긴 이야기나 책 전체의 맥락을 이해해야 하는 질문에 대해 단편적인 정보만 가져온다면, 충분한 답변을 제공하기 어렵게 됩니다.
2. RAPTOR의 핵심 아이디어
RAPTOR (Recursive Abstractive Processing for Tree-Organized Retrieval)는 문서를 단순한 청크의 집합이 아니라, 여러 수준의 추상화를 갖는 트리 구조로 재구성합니다.
즉, 문서를 아래와 같은 단계로 처리합니다.
- 청크 분할
- 문서를 문장이 중간에 잘리지 않도록 주의하면서 일정 크기의 청크로 나눕니다.
- 임베딩 및 클러스터링
- 각 청크를 SBERT와 같은 임베딩 모델로 벡터화합니다.
- 고차원 임베딩의 문제를 해결하기 위해 UMAP(Uniform Manifold Approximation and Projection)으로 차원 축소 후, Gaussian Mixture Models (GMM)을 이용해 소프트 클러스터링을 수행합니다.
- 소프트 클러스터링 덕분에 한 청크가 여러 군집에 속할 수 있어, 문서의 복합적 주제를 보다 유연하게 반영할 수 있습니다.
- 모델 기반 요약
- 클러스터에 속한 청크들을 LLM(예: gpt-3.5-turbo)을 사용하여 요약합니다.
- 이 요약문은 해당 클러스터(노드)의 대표 내용이 되며, 상위 노드로 올라가게 됩니다.
- 재귀적 적용
- 위의 과정을 반복하여, 하위 청크들이 모여 상위 요약을 형성하고, 최종적으로 문서를 전체적으로 대표하는 트리 구조가 완성됩니다.
- 트리의 리프 노드는 원문 청크를, 부모 노드는 그 청크들을 요약한 정보를 담습니다.
3. 질의 응답 시의 활용 방식
문서 전체를 계층적으로 요약해 놓은 트리를 기반으로, 사용자 질의에 대해 두 가지 방식으로 정보를 검색합니다.
① 트리 순회 방식 (Tree Traversal)
- 과정:
- 트리의 최상위(루트) 노드부터 시작해, 각 노드와 질의의 코사인 유사도를 계산합니다.
- 가장 유사도가 높은 상위 노드들을 선택한 후, 그 자식 노드들에서 다시 코사인 유사도가 높은 노드를 선택합니다.
- 이런 식으로 하위 레벨로 내려가면서 점점 구체적인 정보를 모읍니다.
- 장점:
- 질문에 맞는 적절한 추상화 수준(상위 주제부터 하위 세부사항까지)을 순차적으로 제공할 수 있습니다.
② Collapsed Tree 방식
- 과정:
- 트리의 모든 노드를 하나의 평면(플랫)으로 펼친 후, 전체 노드 중 질의와의 코사인 유사도가 높은 순서로 선택합니다.
- 선택된 노드들을 이어붙여 최대 토큰 수에 맞게 정보를 구성합니다.
- 장점:
- 모든 레벨의 정보를 한 번에 고려할 수 있어, 특히 정보의 세부 조정이 필요한 질문에 더 유연하게 대응합니다.
- 실제 실험에서는 이 방식이 더 우수한 성능을 보였습니다.
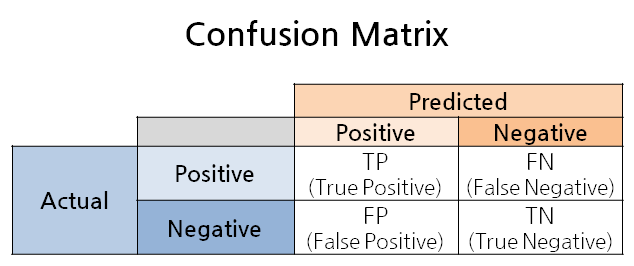
4. RAPTOR의 주요 장점과 실험 결과
- 종합적 문맥 이해:
- 단순 청크 기반 검색보다 문서 전체의 주제 및 세부 정보를 동시에 활용할 수 있습니다.
- 효율성:
- 트리 구조 구축 과정은 선형 시간 복잡도로, 대용량 문서 처리에 적합합니다.
- 실험 결과:
- NarrativeQA, QASPER, QuALITY와 같은 다양한 QA 데이터셋에서 기존 retrieval 방식보다 뛰어난 성능을 보였습니다.
- 특히, GPT-4와 함께 사용할 경우 QuALITY 벤치마크에서 약 20%의 성능 향상이 확인되었습니다.
- 추가 고려사항:
- 요약 과정에서 약 4% 정도의 경미한 허위 정보(hallucination)가 발생할 수 있으나, 상위 노드로 집계되면서 그 영향은 크게 줄어듭니다.
5. 추가 배경 및 관련 연구
- 기존 방법과의 차별점:
- 전통적인 retrieval 방식은 단순히 문서의 인접한 청크만을 사용해 정보 검색을 수행하는 반면, RAPTOR는 문서의 여러 부분에서 멀리 떨어진 연관 정보를 효과적으로 그룹화하여, 보다 포괄적이고 계층적인 문맥 정보를 제공합니다.
- 유사 연구:
- 최근 연구에서는 대형 언어 모델에 retrieval augmentation을 적용해 최신 정보와 긴 문맥을 처리하려는 시도가 많았습니다.
- RAPTOR는 이런 노력 중 하나로, 단순 청크 기반 접근 방식의 한계를 극복하고, 다단계 추론이 필요한 복잡한 질문에 대해 우수한 성능을 발휘합니다.
결론
RAPTOR는 문서를 단순한 청크들의 나열이 아니라, 다양한 추상화 수준을 가진 트리 구조로 재구성하여, 질문에 맞는 적절한 정보(상위 주제부터 세부사항까지)를 효과적으로 검색하는 혁신적인 방법입니다. 이 방식은 긴 문서나 복잡한 텍스트를 다룰 때, 기존의 retrieval 기법보다 훨씬 더 포괄적이고 정교한 답변을 생성할 수 있도록 도와줍니다.
이와 같이, RAPTOR는 retrieval-augmented 언어 모델의 한계를 극복하고, 다단계 추론 및 복잡한 질문 응답 시스템에서 중요한 진전을 이루고 있다고 할 수 있습니다.